Problems
Convolutional Neural Networks (CNNs) have long been the preferred model for object recognition due to their robustness, ease of control, and relatively simple training process. Even when trained on millions of images, they handle overfitting well and perform nearly as well as standard feedforward neural networks of comparable size. However, CNNs are challenging to apply to high-resolution images. At the scale of ImageNet, an innovation was needed to optimize GPU usage, reduce training times, and enhance overall performance.
Dataset
ImageNet is a dataset containing over 15 million labeled high-resolution images spanning roughly 22,000 categories. The images were sourced from the web and labeled by human workers using Amazon’s Mechanical Turk.
Since ImageNet contains images of varying resolutions, the authors down-sampled all images to a fixed resolution of 256×256 pixels to meet the requirements of their system. For rectangular images, they first resized the shorter side to 256 pixels, then cropped the central 256×256 patch. The only preprocessing applied was subtracting the mean pixel activity from the training set; the network was trained on the raw, centered RGB pixel values.
The Architecture
The architecture is composed of eight layers: five convolutional layers and three fully connected layers. However, what sets AlexNet apart isn’t just its structure; it’s the innovative features and techniques introduced, which represent new approaches to convolutional neural networks.
ReLu Nonlinearty
AlexNet uses Recitified Linear Units(ReLU) instead of the tanh or sigmoid neurons. The reason is deep convlutional nerual networks with ReLus train serveral times faster
ReLU: f(x) = max(0,x)
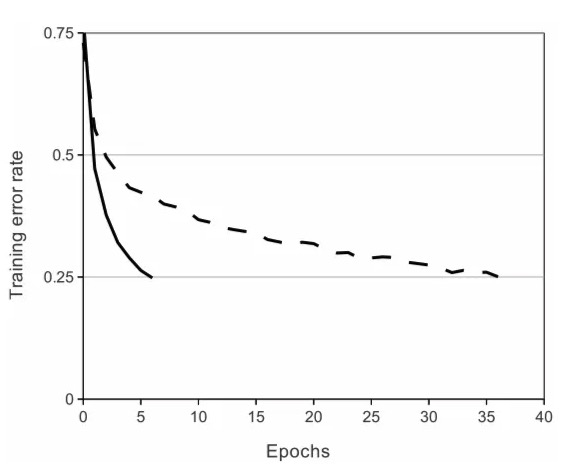
A four-layer convolutional nerual network with ReLus(solid line) reaches a 25% training error rate on CIFAR-10 six times faster than an equivalent network with tanh neurons(dashed line).
Multipe GPUs
Back then, GPUs had only 3GB of memory, making it hard to train on 1.2 million images. AlexNet solved this by splitting the model across two GPUs, enabling larger models and faster training times.
Overlapping Pooling
In traditional CNNs, pooling layers summarize the outputs of neighboring neurons in the same kernel map without overlap. However, the authors propose using overlapping pooling, where a pixel appears multiple times. They noted that models trained with overlapping pooling were slightly more resistant to overfitting. This approach also reduced their top-1 and top-5 error rates by 0.4% and 0.3%, respectively.
Overal Architecture

Reduce Overfitting
Data Augmentation
The authors applied label-preserving transformations to artificially expand the dataset, generating image translations and horizontal reflections, which increased the training set size by 2048 times.
They also conducted Principal Component Analysis (PCA) on the RGB pixel values to adjust channel intensities, resulting in a reduction of the top-1 error rate by more than 1%.
Dropout
The authors apply droput with a probability of 0.5 in the last two fully connected layers, which I believed is a heavy regularization.
This means that every iteration uses a different sample of the model’s parameters, which forces each neuron to have more robust features that can be used with other random neurons. However, dropout also increases the training time needed for the model’s convergence.
Insights
LeNet was the first successful application of neural network on MNIST, a quite small dataset from today’s view. However, due to the limited computing power and storage of the computers at the time, neural network could not be applied to other bigger datasets and more complicated problems. SVM was the trend for about 20 years after LeNet. By 2012, the original bottleneck of neural network, computing power and storage, was improved a lot. This made AlexNet possible to emerge and eventually pulled people’s attention back to neural network. Overall, AlexNet was able to compute the much larger dataset ImageNet (larger images, higher number of images and classes) and improved the accuracy substantially.
Compare AlexNet to SVM: AlexNet doesn’t need to hand craft features while SVM strongly relies on feature engineering. When we have complicated problems, AlexNet apparently provides a much easier and more accuracy approach.
Compare AlexNet to LeNet: Both nets are CNN which considers spatial relationship. AlexNet can be considered as a bigger and deeper LeNet (therefore more accurate). The major improvements of AlexNet include dropout layer (reduce overfitting), using ReLu instead of sigmoid (reduce gradient vanishing), MaxPooling (make the model more robust to image shift; I feel it is a regularization as well), image augmentation (make the model more robust to the changes of image).
Overall They correctly demonstrate that a large deep convolutional neural network is capable of achieving record-breaking results on a highly challenging dataset using purely supervised learning, without any pretraining. They showcase that things like ReLU and dropout are vital to training deep models. They note that the network’s performance degrades even if a single convolutional layer is removed, indicating that depth is highly important. They also didn’t use any unsupervised pre-training even though it might help a lot with the training process, as it simplified their experiments.
Reference
ImageNet Classification with Deep Convollutional Nerual Networks